Zhuoran Jin
Fourth-year Ph.D student@Institute of Automation, Chinese Academy of Sciences

I am a 4th-year Ph.D student at the Natural Language Processing and Knowledge Engineering Group (NLPKE), Institute of Automation, Chinese Academy of Sciences (CASIA). I am fortunate to be advised by Prof. Jun Zhao. Before that, I obtained my B.E. degree in Software Engineering from Northeastern University (NEU) in 2021. My research interests include natural language processing, large language models, and knowledge engineering.
My research is dedicated to bridging the gap between large language models and human knowledge frameworks, with a focus on expanding knowledge boundaries, erasing harmful knowledge, and improving reasoning capabilities. Recently, I have also become increasingly interested in multimodal large language models, particularly in understanding and enhancing their ability to automatically solve complex and meaningful real-world problems. My primary research areas are:
- Retrieval-Augmented Generation: RAG can effectively expand the internal memory boundaries of LLMs by providing external context. My work focuses on: (1) leveraging feedback reward signals from LLMs to improve retrieval quality (InstructoR, EMNLP 2023); (2) investigating the mechanisms underlying knowledge conflicts between internal memory and external context (Tug-of-War Between Knowledge, COLING 2024 and Cutting Off the Head Ends the Conflict, ACL 2024); and (3) aligning RAG model behavior with human preferences through reward modeling (RAG-RewardBench, ACL 2025).
- Machine Unlearning: Machine unlearning enables the targeted removal of sensitive, harmful, or copyrighted knowledge from models. To better evaluate unlearning in the domain of LLMs, we propose a Real-World Knowledge Unlearning benchmark (RWKU, NeurIPS 2024). Building on this, we reveal the vulnerability of existing unlearning algorithms to adversarial attacks and propose Latent Adversarial Unlearning for robust unlearning (LAU, AAAI 2025). Moreover, to improve the naturalness of model responses after unlearning, we introduce an on-policy reinforcement learning framework that performs refusal boundary optimization (RULE).
- Multimodal Reasoning: Multimodal reasoning is a core capability for AI systems to solve real-world tasks. However, the extent to which current models have truly advanced in this ability remains unclear. To address this gap, my research mainly involves: (1) exploring what multimodal CoT reasoning can and cannot do, and revealing the reasoning limitation known as “Look Shallow, Think Deep” (Look Shallow, Think Deep); (2) proposing a benchmark for multimodal video reasoning that exposes the challenges current models face in conducting long-range, multi-frame inference (MMR-V).
- Reward Modeling: Reward models serve as a critical proxy for human values, guiding optimization in RLHF. We explore reward modeling in the contexts of RAG (RAG-RewardBench, ACL 2025), agent (Agent-RewardBench, ACL 2025), and omni-modal scenarios (Omni-Reward).
If you are interested in my work or want to collaborate, feel free to contact me via: zhuoran.jin[at]nlpr[dot]ia[dot]ac.cn.
News
| May 26, 2025 | Three papers are released on arXiv, exploring omni-modal reward modeling, demystifying multimodal CoT reasoning, and benchmarking multimodal video reasoning. |
|---|---|
| May 16, 2025 | Five paper are accepted by ACL 2025. |
Selected Publications
- arXiv
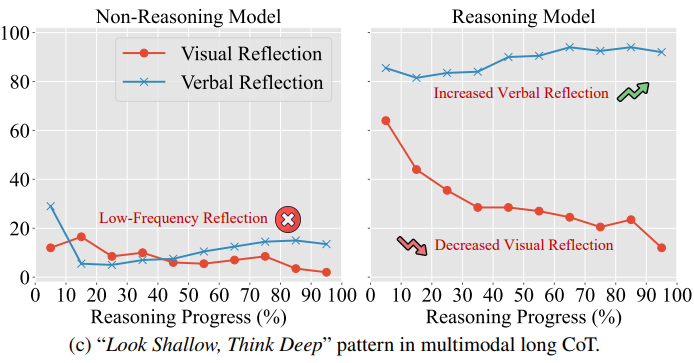 Look Shallow, Think Deep: What Multimodal Chain-of-Thought Reasoning Can and Cannot DoarXiv preprint (arXiv), 2025
Look Shallow, Think Deep: What Multimodal Chain-of-Thought Reasoning Can and Cannot DoarXiv preprint (arXiv), 2025









